The following sections are aimed at RAMSES Logic developers and contributors. If you simply
want to use the library, stop reading here, unless you are interested in the internal workings
of the code and are not afraid of technical details!
Understand RAMSES Logic architecture and design¶
Current Architecture¶
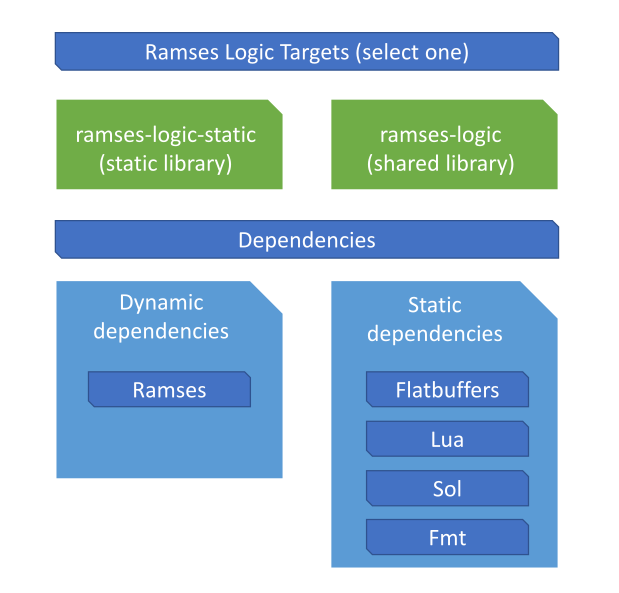
The Ramses Logic consists of a single library which can be static or dynamic.
It has a dependency on a Ramses target which can be static or dynamic library
itself, or a custom build of Ramses. The following diagram illustrates the
libraries and their dependencies:
Note
By default, the Logic Engine builds a client-only shared library version of
Ramses. You can override this behavior by providing your own Ramses target as
described in the Build options.
Source contents¶
The following list gives a rough overview which parts of the logic engine reside in which part of the source tree:
- include/
Contains all public include files
- lib/
- flatbuffers/
Schema files describing the flatbuffers file structure and generated flatbuffer headers
- impl/
API classes and their corresponding Impl classes (following the pimpl pattern)
- internals/
Classes which contain the implementation details. This is the majority of the code.
- cmake/
CMake helper files
- examples/
Contains examples, each in its own folder
- external/
Contains all external dependencies, as described in the Current Architecture
- doc/
The docs source files and configuration (Sphinx and Doxygen)
- unittests/
Unit tests, each file corresponding to a (unit) class or a subset of its functionality
Note
The minimal set of files/folders required to build the logic engine is /include, /lib, /cmake, /external and the root CMakeLists.txt file.
API, ABI and file format changes¶
The Logic Engine public API resides in the include folder of the project. Any change there
should be considered a possible API or ABI change. File format schemas are stored in the lib/flatbuffers
folder - changes there can break existing binary files. All of those changes should be combined with
corresponding entry in the CHANGELOG and considered for a non-patchfix bump when creating a new release.
Version bump rules generally comply with semver semantics. Listing some examples here:
Changing existing API or breaking serialization format results in major version bump. Read the flatbuffers article on writing schemas has useful hints how to write forward-and-backwards compatible schemas and code
Changing Lua syntax which may break existing scripts’ results in major version bump
One exception to this rule is handling Lua errors which would otherwise introduce undefined behavior in the scripts. We consider these fixes non-breaking, but always mention them explicitly in the CHANGELOG
Adding a new method or class which can compile with existing code results in minor version bump
Changing internal functionality with no user visibility results in a patchfix bump.
Note
Practical hint for developers: all flatbuffer fields are by default optional. Adding a new field
at the end of a table and checking for its existence in code when loading a file makes the file format change by
default forward-and-backwards compatible.
I want to understand the code, where do I start?¶
A good place to start learning the Logic Engine is to be a user of it first. Have a look at the
examples. Check out the API classes and follow
some of the methods through their implementation. Interested in the behavior of some of the classes?
Take a look at its unit test in the /unittests folder.
Since the Logic Engine makes heavy use of Lua through the (amazing!) Sol library you
will sooner or later stumble upon sol::* symbols when digging through the code. We suggest to study the concepts of Sol beforehand through its (well designed) documentation
and tutorials, before trying to make sense of the Logic Engine customization points.
Have a good grasp of Sol and Lua? We suggest diving into the Logic Engine by first looking into the implementation of the
LuaScript class (the actual code is in LuaScriptImpl - a standard practice of the Pimpl pattern used for the entire API).
Looking and debugging through the unit tests of LuaScript(Impl) is also a good way to understand the inner workings of the class.
Other classes (bindings for example) share similar concepts and will be easy to understand.
Design decision log¶
The following list documents the design decisions behind the RAMSES Logic project in
inverse-chronological order (latest decisions come on top).
- Do we support animations?
Yes. After brainstorming different options, we decided animations belong to the logic/scripting runtime rather than the Ramses scene API. As a result, animations will be removed from Ramses in a future release and only maintained in the Logic Engine.
- How to implement serialization?
Serialization is implemented using Flatbuffers - a library which allows binary optimizations when loading objects which are flat in memory.
- Static vs. shared library
Both are supported, but shared lib is the preferred option. The public API is designed in a way that no memory allocation is exposed, so that DLLs on Windows will not have the problem of incompatible runtimes.
- Which version of
C++to use? As with CMake,
C++version is a tradeoff between modern code and compatibility. We settled onC++17so that we can use some of the modern features likestring_view, andstd::optionalandstd::variant.
- Which version of
- Which version of``CMake`` to use?
CMakeis an obvious choice for any C/C++ project as it is de-facto industry standard for cross-platform development. There is a tradeoff between cleaniness and compatibility when choosing a minimal CMake version, and we settled on version 3.13, despite it being relatively new and not installed by default on the majority of Linux distributions. CMake made great improvements over the last few versions, and 3.13 specifically offers much better ways to install and package projects, as well as many QoL changes.
- Which tool to use for documentation
We use a combination of Doxygen, Sphinx and Breathe. Doxygen because it has great support for inline C++ documentation and lexer capabilities. Sphinx because it is industry standard and provides great flexibility in putting multiple different projects under the same umbrella. Breathe is a bridge between Doxygen and Sphinx which provides beautiful html output from raw Doxygen output.
- Plain
Luavs.Solwrapper Since
Luahas a low-level API in C which requires careful handling of the stack as well as working with raw pointers and casts, we decised to usesol- a great C++ wrapper for Lua which also provides easy switch between differentLuaimplementations with negligable performance overhead.
- Plain
- Should scripts interact between each other?
One of the difficulties of script environments is to define boundaries and state of scripts. It is often required that data is passed between scripts, but it is highly undesirable that scripts global variables influence each other and create unexpected side effects. To address this we put each script in its own
Luaenvironment, but allow scripts to pass data to each other by explicitly linking one script’s output(s) to another script’s input. This can be done during asset design time or during runtime.
- Pimpl, no Pimpl, or Header-Only?
Header-Only implementation was almost immediately out of question due to the expected size and feature scope of the
Logic Engine- which includes animations, scripts, serialization, among other things. Between Pimpl and no Pimpl, we decided to lean on our experience from developing Ramses, where having a Pimpl abstraction proved very useful when guaranteeing a stable API and under-the-hood bugfixing and performance improvements.
- What is the interface of scripts to the
RAMSES Logicruntime? Based on the latter decision, we had to define how
Luascripts interact with the C++ side of the runtime. After lengthy discussions and considering various different options, we settled on a solution where eachLuascript declares explicitly its interface via a special function with the same name. There is a differentiation between inputs and outputs which also defines when a script will be executed, namely when it’s inputs values changed. Script payload must be placed in another special function calledrunwhich can access inputs as declared, and also set outputs’ values.
- What is the interface of scripts to the
- How should scripts interact with the
RAMSESscene(s)? Luaoffers multiple ways to interact between scripts and C++. The two main options we considered:provide custom classes and overload them in C++ code (e.g. RamsesNode type in
Lua)provide interface in
Luato set predefined types (e.g. int, float, vec3, etc.) and link them to C++ objects
We chose the second option because it allows decoupling of the
Luascripts from the actual 3D scene, and also allows theRAMSES Composerwhich uses theLuaruntime to generically link the scripts properties toRAMSESobjects.
- How should scripts interact with the
- Which tools to use for CI/testing?
All CI tools are based on Docker for two reasons: Docker is industry standard for reproducible build environments, and it nicely abstracts tool installation details from the user - such as Python environment, extensions, tool versions etc. Also, the Docker image recipe can be used as a baseline for a custom build environment or debug build issues arising from using special compilers. The concrete tools we use for quality checks are: Googletest, clang-tidy, valgrind, and a bunch of custom python scripts for license checking and code-style. We also use llvm tools for test coverage and statistics.
- Which approach to use for continuous integration?
There are multiple open platforms for CI available for open source projects, but all of them have limitations, mostly in the capacity. Therefore we chose to use an internal commercial CI system for the initial development of the project in order to not hit limitations. It is planned to switch to an open platform in future (i.e. Github actions, CircleCI or similar).
- Should we support JIT compilation of scripts?
Currently we use standard Lua, no JIT, but we maintain the possibility to switch to LuaJIT in the future.
- Which version of
Lua? We chose Lua 5.1 as it is still compatible with LuaJIT and enables potentially compiling scripts dynamically in a performance-friendly way.
- Which version of
- Which scripting language to use?
Luawas an easy choice, because it provides by far the best combination between extensibility and performance. The stack concept of Lua provides unprecendented flexibility for custom extensions in C++ code, and the metatable approach provides great way to provide object oriented features in a pure scripting language. The other option we considered was Python due to its power and popularity, but ultimately ruled out as an option due to the size of the interpreter itself and the complexity of it which is not required for real time graphics applications.
- Should we make separate library or embed support in
RAMSESdirectly? RAMSESis designed to be minimalistic and closely aligned to OpenGL. Even though it would be more convenient to have a single library, we decided it’s better to create a separate lib/module so that users which don’t need the scripting support are not forced with it, and we can also be more flexible with the choice of technology.
- Should we make separate library or embed support in
- Should scripts be executed remotely (renderer), or client-side only? Or both?
RAMSESprovides distribution support for graphical content - in fact that’s the primary feature ofRAMSESthat distinguishes it from other engines. We had the choice to whether to make scripting execution also remote (i.e. executed on a renderer component rather than a client component). There are pros and cons for both approaches, but ultimately we decided to implement a client-side scripting runtime in favor of security and stability concerns. Sending scripts to a remote renderer poses a security risk mostly for embedded devices which must fulfill safety and quality criteria, and the benefits of executing scripts remotely is comparatively small.
- Should we add scripting support to
RAMSES? As more and more users of
RAMSESuse the rendering engine, various applications had to find a solution to the lack of scripting capabilities. We tried several solutions - code generation, proprietary scripting formats, as well as implementing everything in C++ purely. Reality showed that these solutions do very similar things - abstract and control the structure of ramses scene(s) and they even shared the same code, for e.g. animation, grouping of nodes, offscreen rendering. Thus we decided that scripting support would provide a common ground for implementing such logic and abstraction.
- Should we add scripting support to
Developer guidelines¶
Apart from the general project architecture and design decisions outlined above, we try to be as open to change as possible. Want to try out something new? Feel free to experiment with the codebase and propose a change (see contributing).
Here are some additional things to consider when modifying the project:
Execute existing tests before submitting PRs and write new tests for new functionality
Have an idea or feature request? Feel free to create a Github issue
Treat documentation at least as good as the code itself
Added a new feature? Mention it in the CHANGELOG!
Modified the public API? Adapt the doxygen documentation!
Changed the serialization format? Re-run the FlatbufGen target in CMake
Made an API, ABI or any other incompatible change? Don’t forget to bump the semantic version of the project in the main CMakeLists.txt file
Note
When changing the serialization schemes of Ramses Logic, the generated flatbuffers header files have to be
re-generated and committed as part of the change. This may seem counter-intuitive for code generation, but not
all build system support dynamically generated code. Hence, we keep the generated header files checked in with
the rest of the code, and re-generate them when needed. To re-create those files, execute the FlatbufGen target
on your build system.
Contributing¶
Pull requests¶
All contributions must be offered as GitHub pull requests. Please read Github documentation for more info how to fork projects and create pull requests.
Please make sure the PR has a good description - what does it do? Which were the considerations while implementing it, if relevant? Did you consider other options, but decided against them for a good reason?
Commit guidelines¶
There are no strict rules how commits have to be arranged, but we offer some guidelines which make the review easier and ensures faster integration.
Make smaller but expressive commits¶
Commits should be small, yet expressive. If you apply a renaming schema to all files in the repository, you should not split them in hundreds of commits - put them in one commit, as long as the reviewer can see a pattern. If you implement multiple classes/libraries which build on top of each other, could be reasonable to split them in multiple commits to “tell a story”. If you need to forward fix something - it’s ok to have a “FIX” commit, don’t have to rebase the whole branch. This works especially well after a first review round, when you want to only fix a reviewer’s comment without rewriting the code.
Bundle commits into multiple PRs when it makes sense¶
If you have a complex feature which can be split into multiple, smaller PRs, in a way that some of them can be integrated earlier than others, then do so. For example, if you need some refactoring before you add the actual feature, and the refactoring makes sense in general even without the new feature - then consider creating two PRs. This increases the chances that the refactoring is merged earlier, thus avoiding conflicts and rebases, while the feature is subject of further discussion and refinement.
Note
When submitting multiple PRs which depend on each other, please mark their dependency by adding a line like this: “Depends-On: <change-url>” where <change-url> is a link to another PR which needs to go in first.
Review¶
All code is subject to peer review. We try to be objective and focus more on technical question rather than cosmetic preferences, but all reviewers are human and inevitably have preferences. We try to acknowledge that everyone has their own style, but we also try to keep things consistent across a large codebase. We strive to maintain friendly and helpful language when reviewing, give concrete suggestions how things could be done instead, in favor of just disliking a piece of code.
Review requirements¶
Before asking for review, please make sure the code works, there are unit tests (even for proof-of-concept code), and there are no code style or formatting violations. The PR source branch has to be based on the latest released branch HEAD revision, unless the requested change is a hotfix for an existing release. Please don’t rebase branches after you asked for a review, unless the reviewer explicitly asked for it. You can merge the latest HEAD of the target branch into the PR source branch, if you need a change that was integrated after the first review round.
Review steps¶
As soon as a PR is created, it will be looked at by a reviewer. If you want to signal that it’s being worked on/changed, put a WIP in the name, or add a WIP label. After a review round, address the comments of the review, and wait for the reviewer to mark them as ‘resolved’. Once everything is resolved, the PR will enter the integration process.
Code style¶
The code style is checked using LLVM tools (Clang-tidy) as well as a custom Python-based style script which performs additional checks. Both checks have to be successful before code can be meaningfully reviewed.
Clang Tidy¶
Clang-tidy is performed as an automated build step within the continuous integration pipeline. Check its documentation for instructions how to execute it locally before submitting code.
Custom style check¶
Some things can’t be easily checked with off-the-shelve tools, so we have our own scripts to check them (we are generally trying to shift towards established tools when possible). For example license headers, header guards, or tab/space restrictions. You can execute those scripts on your local machine with Python like this:
cd <source_root>
python3 ci/scripts/code_style_checker/check_all_styles.py
Additional conventions¶
When it comes to code style, not everything can be checked automatically with tools. The following list describes additional conventions and style patterns used throughout the project:
- Namespaces
All code must be in a namespace. Code in namespaces is indented. Nested namespaces must use the compact C++17 notation (namespace1::namespace2::namespaces3)
// Good namespace namespace1::namespace2 { class MyClass; } // Bad namespace namespace1 { namespace namespace2 { class MyClass; } } // Also bad namespace namespace1{ namespace namespace2 { class MyClass; } }
- Usage of
auto The C++ community is divided when it comes to usage of the
autokeyword. Therefore we don’t enforce strict rules, except for some concrete cases listed belowWhen declaring primitive types (int, strings, bool etc.), don’t use auto:
// Good std::string myString = "hello"; // Bad auto myString = "hello";
When using template functions which have the type as explicit template parameter, don’t repeat it but use auto instead
// Good auto myUniquePtr = std::make_unique<MyType>(); // Bad std::unique_ptr<MyType> myUniquePtr = std::make_unique<MyType>();
When using loops and iterators, use auto, but don’t omit const and reference qualifiers if used
// Good for(const auto& readIterator : myVector) { std::cout << readIterator; } // Bad for(const std::vector<MyType>::iterator readIterator : myVector) { std::cout << *readIterator; }
When using loops and iterators, use auto, but don’t omit const and reference qualifiers if used
// Good for(const auto& readIterator : myVector) { std::cout << readIterator; } // Bad for(const std::vector<MyType>::iterator readIterator : myVector) { std::cout << *readIterator; } // Bad for(auto readIterator : myVector) { // code which doesn't require non-const access to readIterator }
For all other cases, apply common sense. If using
automakes it more difficult to understand/read the code, then don’t use it. If the type is obvious and auto makes the code more readable, use auto!
- Usage of
Continuous integration¶
There is no support for a public CI service yet, it will be added in the future. If you want to contribute to the project, you can ensure your code gets merged quickly by executing some or all of the tests yourself before submitting a PR.
We suggest executing the following set of builds in order to maximize the chance that the PR will be merged without further changes:
A GCC-based build in Release mode (Linux or Windows WSL)
A LLVM-based build in Debug mode (Linux or Windows WSL)
A Visual Studio 2017 CE Release build (Windows)
A CLANG_TIDY run in Docker (Linux or Windows WSL)
A LLVM_L64_COVERAGE run in Docker (Linux or Windows WSL)
The following subchapters explain how to execute these builds.
Testing Windows builds locally¶
You can follow the build instructions for Windows and then execute the RUN_TESTS target of Visual Studio, or use the ctest command in the build folder.
Branching¶
Currently, we don’t maintain multiple branches. We have a single mainline branch where releases are pushed and tagged. After we have reached a level of feature completeness where we feel comfortable to support older branches, we will do so.